

Designing a social network system is not an easy task. As currently social networking systems are the most used internet services with huge, connected users and data generators. These services ingest and flow TBs of data daily. Due to this these systems poses many challenges which need to be addressed such as scalability, security, privacy, moderation, and user experience.
When designing such a system, some of the main challenges include Scalability, High Availability, Performance, and Security. I will not cover Compliances in this post.
In this post, I will try to come up with a system design for Social Networking services with the following basic functional and non-functional requirements.
Functional Requirements
In this post, I am going to touch following functional requirements.
- User management
- Users can follow each other.
- Make a friend.
- Users can post on their own and friends’ timelines and can post photos, Videos, and other media.
- Should be able to see posts with likes and comments.
- Followers/Friends can see others’ posts on their timelines.
- Users can like and comment.
- Users should get a notification for likes, comments, follow, and friends’ requests.
- Very Basic analytics for Post encasements, User activity, Hash Tag Trends, etc.
Non-Functional Requirements
Social networking services are platforms that allow users to interact with each other through various types of media. Users can post text, photos, videos, and other content, as well as like, comment, and share them with their connections. These activities generate terabytes of data every day, which need to be stored and processed efficiently. Social network systems are designed to handle more read operations than write operations, so they must be optimized for performance and scalability.
- Scalability
- High Availability
- Performance
- Security
Storage Size Estimation
A simple storage estimation will help in understanding scalability and performance requirements. For this check table below.

Imagine a system with 5 million active users who each do 5 activities per day and generate 1 MB of data per activity. That means the system needs 25 TB of storage every day and 9 PB every year. That’s a lot of data to handle, process, and store. It makes the system’s scalability, availability, and performance more challenging, but also more exciting.
Basic Data Modeling for Social Graph
Let’s define basic entities for our social network requirements and establish relationships among them to create a basic graph for our system. Using these related entities our system would be able to create a social graph of our connected users. For more details read this
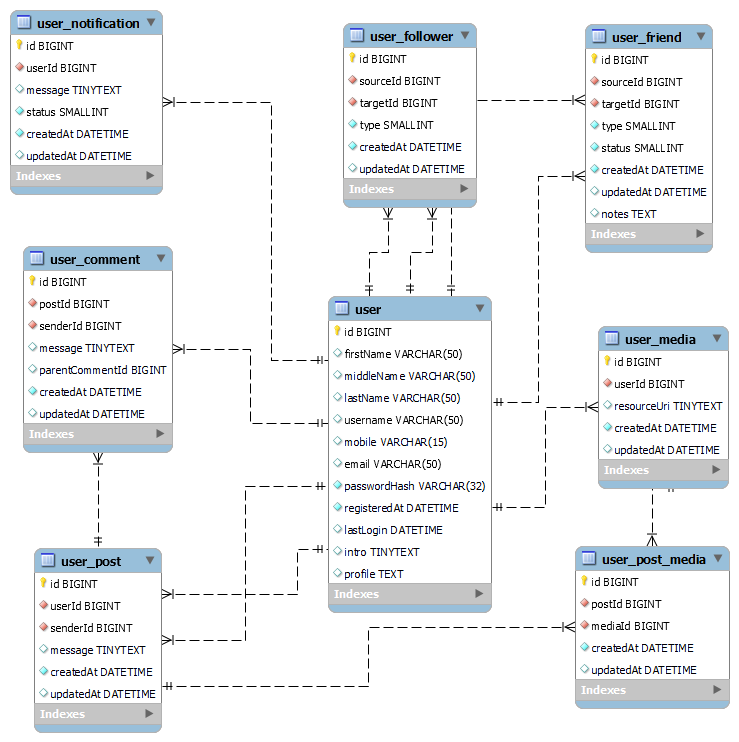
- user: User table to store user information, id is the primary key, email, and mobile number are unique fields.
- user_follower: This table records the user followers and their types. The types can be Like, Dislike, or Follow, indicating how the followers interact with the user
- user_friend: The User Friend Table keeps track of the user’s friends. The friend status column indicates the current state of the friendship and the type column specifies the kind of friendship.
- user_post: The User Post Table stores the posts made by the users. The sender can choose to let other users with the right permissions post on their wall.
- user_comment: The post comment table stores comments by users on posts. The ParentCommentId column would be used to store nested comments.
- user_notification: The user notification table stores notification generated for different events for users with a status column which would be used to track notification status like generated, delivered, and viewed.
- user_media: The metadata and object URI of the media files uploaded by users and included in their posts will be stored in this table.
- user_post_media: This table will store information for the media files used in a post.
High-Level View of the System
We are going to design a Social Networking Service where users can register themselves using a client app, then can make friends and follow others. Users can post status text, photos, videos, etc. on their timelines and others as well. Users can view others’ statuses like a comment which is naturally going to make this service high-read and highly eventful (Comments, like, etc.).
First, we are going to describe very high-level components going to be used in this system. Later in this post, we are going to detail these components.
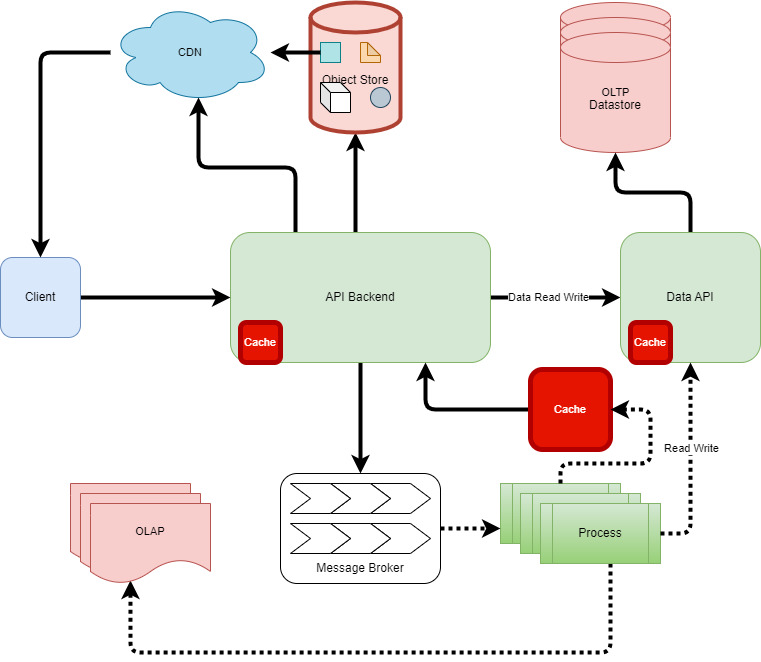
- Client: A social network client application is a software program that allows users to access and interact with a social network service. It may provide features such as browsing, posting, messaging, commenting, liking, sharing, and following other users. A social network client application can be web-based, desktop-based, or mobile-based, depending on the platform it runs on.
- API Backend: The API backend consists of a set of backend API services that handle various operations. These services interact with OLTP Datastore, Object Store, Message broker, and OLAP to store and retrieve information efficiently.
- Data API: This system will offer a layer of abstraction for the underlying database and enable very high-performance read-write APIs for the datastore, allowing the API backend to operate independently.
- OLTP Datastore: To store our data, we need a database system that can handle high volumes of transactions and ensure data availability. This is why we will use an OLTP data store for our OLTP needs. We will use a shared database with global replication to support the Peta Byte scale.
- Object Store: This is a storage system that can handle and deliver any media file. It has high availability and scalability features.
- Message Broker: A message broker is a software component that enables asynchronous communication between different systems or applications by handling events and data with high performance.
- Processes: This component consists of multiple processes that run in the background and handle asynchronous and batch operations. This will communicate with the message broker, OLAP, OLTP, and cache to read input and update results.
- OLAP: These systems are software tools that enable users to analyze data from multiple perspectives and dimensions. We will use this to generate different insights for users.
- Cache: To improve performance and reduce latency, any scalable system needs a cache. Our system will use a cache (both distributed and in-memory) with most of its components.
- CDN: To speed up the delivery of media files, static resources, and post content, we would use CDN. CDN is a network of servers that caches and distributes these assets to the users. This way, we can enhance performance, reduce latency and increase scalability.
All the above components should be designed and used to achieve our functional and non-functional requirements. Let’s keep the client for later or we can keep out of this design scope.
API Backend Design
An API backend is a service that runs behind a load balancer and offers an HTTP-based API for communication with other services or databases. It provides the data, computation, actions, activities, and events that the front-end interface needs to interact with the user.
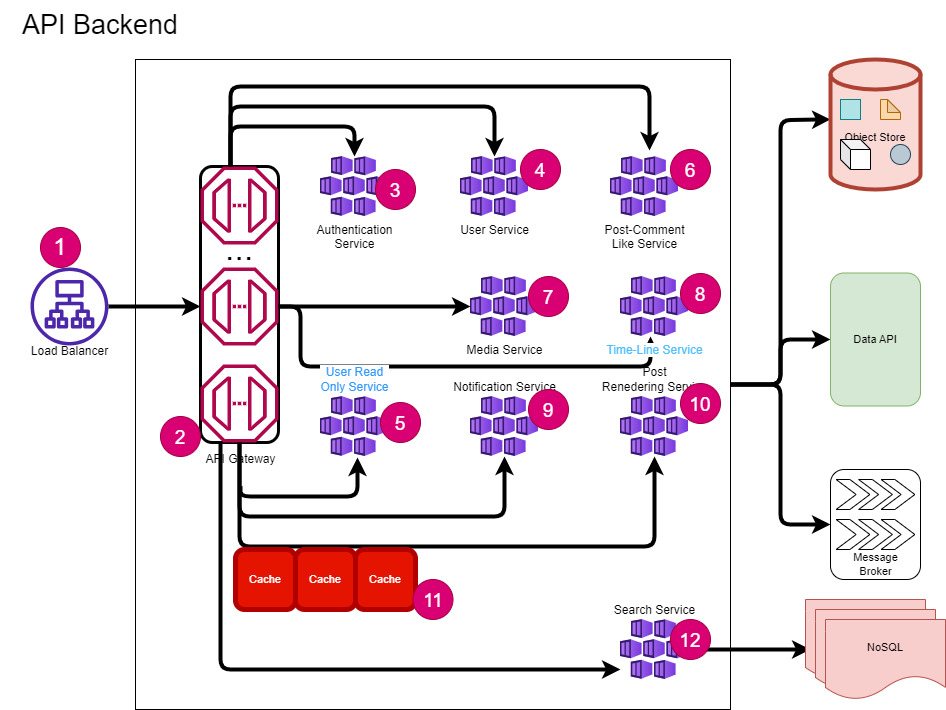
In the case of our Social Networking Service API backend will look like this.
We can use Microservices style architecture for API backends. Frontend and client requests will come through one Application load balancer which will be further routed to API gateways.
API gateways will do some basic checks on request the route request to the respective service. Services will communicate with backing services like database, object store, message queues, and cache and perform operations.
Each service is scalable, highly available, resilient, secure, and concurrent.
- Load Balancer: A load balancer is a device or software that distributes network traffic across multiple servers. It improves the performance, reliability, and scalability of web applications. In our case, this load balance will be Infront of the API gateway service to distribute loads across multiple API gateway servers.
- API Gateway: An API gateway server is a software component that acts as an intermediary between clients and backend services. It provides a single-entry point for all requests and can perform tasks such as authentication, routing, load balancing, caching, and monitoring. An API gateway server can improve the performance, security, and scalability of an application.
- Authentication Service: This service will verify the identity of users and API requests. It will also check the permissions and roles of the users and requests. API Gateway will rely on this service for authentication and authorization.
- User Service: This service allows users to sign up, manage their profiles, and connect with other users.
- User Read-Only Service: This service provides read-only access to user data, such as profile details, friend lists, and follower connections.
- Post Comment Like Service: This service provides API to create and manage posts, comment and liken on posts, etc.
- Media Service: This service will provide functions to upload and manage users’ media used in posts.
- Timeline Service: The timeline service is responsible for creating the timeline data for each user, which shows their activities and updates. The service relies on cached data and other OLAP processes that run in the background to generate the timeline for each user.
- Notification Service: This service is responsible for providing and managing notifications to users of different activities and recommendations. The service relies on other service data, cached data, and other OLAP processes that run in the background to generate the notification for each user.
- Post Rendering Service: This service is responsible for displaying posts. It will access the post content, media information, comments, and likes, and send them to the user application for rendering. This service can also use CDN to reduce latency and enhance performance.
- Cache: To reduce the delay and enhance the efficiency of any social media platform that handles a lot of read requests, we will employ a distributed cache system along with all services.
- Search Service: This service will act as a proxy to the OLAP database, free text search, analytics results, etc.
Data API Design
Data API is an abstraction over the OLTP database to Backend API services. It will provide API to perform the read and write of data. All underlying operations like Shard Identification, database connection, and unique id generation for each record will be done by this component.
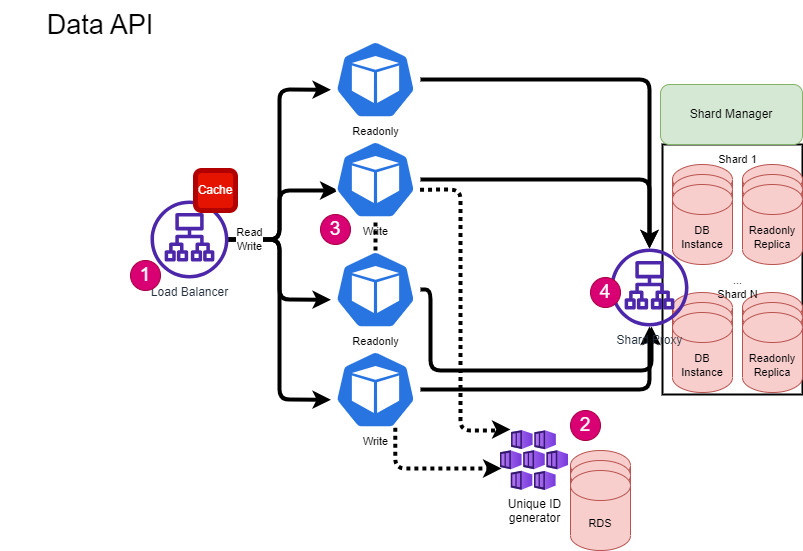
- Load Balancer: This Load balancer will distribute read/write data requests based on the shard key. Underlying services would be connecting to assigned shard db to perform database operations via Shard Proxy.
- Unique ID Generator: This service will be used to generate global unique database id keys only. This service will have n nodes across the data center connected via a gatekeep to generate a unique id for database table keys. This service can be discussed in a separate post. System design : Distributed global unique ID generation | by Sandeep Verma | Medium
- Data API Nodes: For read operations only a read replica of a shard will be used and for write operation master node of the shard will be used. Each node has a connection pool of assigned shards. We can use a gatekeeper to shard assignments and rebalance dynamically.
- Shard Proxy: This component routes requests based on sharding keys. It is essential for the whole system and may need a third-party or open-source solution. Alternatively, one can create it using custom techniques. This component deserves a separate topic for discussion.
OLTP Datastore Topology
Online transaction processing (OLTP) is the term for using computer systems to manage transactional data. OLTP systems capture and store the data from business interactions that happen in the daily operations of the organization and allow querying of this data to draw conclusions.
For this service, we will use RDBMS as this is best suitable for structured and transactional databases with strong consistency.
But all transactional features of RDBM create challenges in achieving scalability, availability, and performance for the Peta Byte scale. This scale cannot be achieved out of the box from RDBMS systems. We need to go for some Enterprise grade licensed database systems like Oracle, Google Cloud Spanner, or some third-party managed Open-source databases.
To handle massive amounts of data with open-source RDBMS, we need to design systems that can manage shards, connections, and some aspects of replication. This is the approach that Facebook, Twitter, and other companies use.
We can think of the following sharded RDBMS topology with across-data center replication for our service.
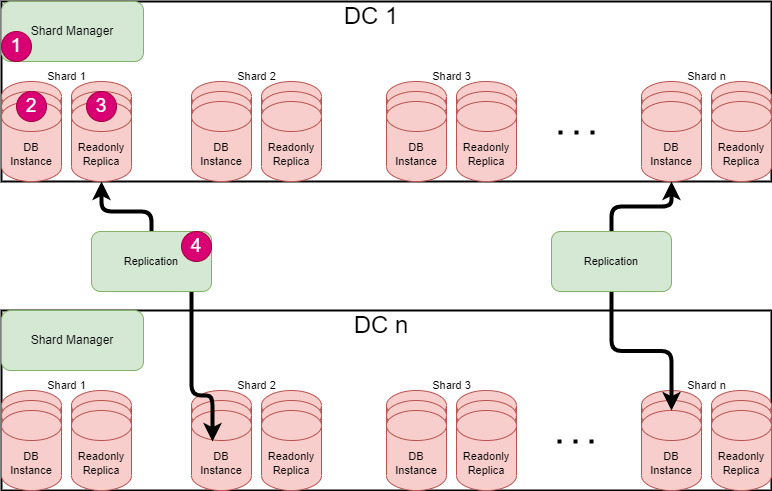
- Shard Manager: The Shard Manager is in charge of handling the distribution and coordination of shards among different data centers. It can also create new shards or delete existing ones, and adjust the shard allocation as needed.
- DB Instance: This is the master node of a shard. This topology will support multi-master replication across data centers.
- Read-only Replica: Read-only replica is replicated data node of a shard this can be used for reading and standby nodes and also for any failover. For each shard replication will be across data centers for high availability.
- Replication: This component will be used to manage the replication of the shard.
Events and OLAP
For social network event real-time and analytics processing, we need one highly scalable Message Broker to ingest millions of messages per minute and one highly scalable OLAP database (No SQL) with text-based search and analytics capabilities. To handle a burst of query requests to OLAP we will use one proxy in API Backend.
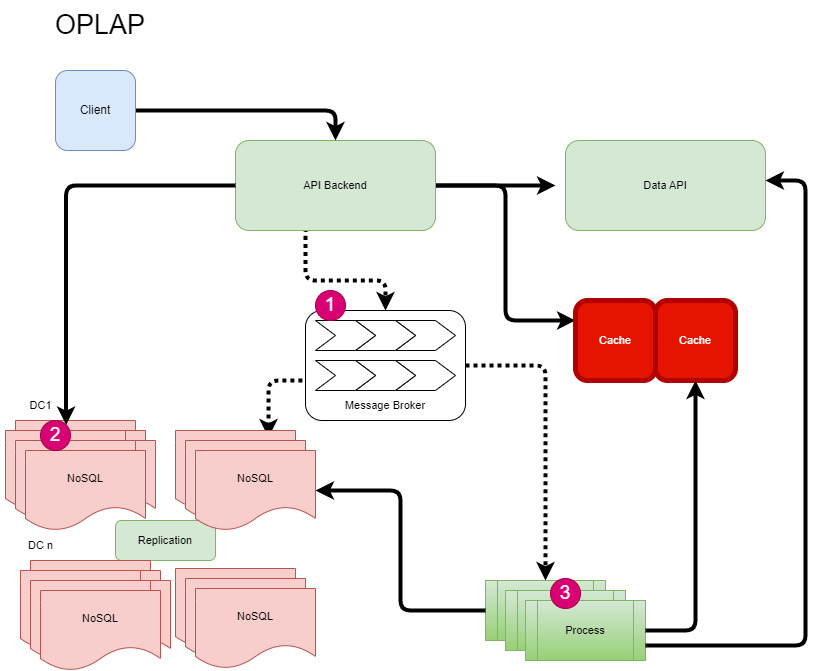
- Message Broker: All events will be pushed to message broker topics for asynchronous processing. The broker processor process will process messages and store them in the NoSQL database.
- API Backend will also update some data like text posts and comments to NoSQL for search and analytics.
- Process: These are message and batch processes and those will also update the cache, OLTP, and OLAP database with analytics and aggregation results.
Database Table Partitioning & Duplication
In Database partitioning, You can split tables, indexes, and index-organized tables into smaller parts, which makes it easier to manage and access these database objects. Most of the Database engines including open-source community editions support different types of table partitioning which is transparent in SQL and can be used with any application. Read more here
- MySQL :: MySQL 8.0 Reference Manual :: 24 Partitioning
- Partitioning Overview (oracle.com)
- PostgreSQL: Documentation: 15: 5.11. Table Partitioning
Table partitioning in a single node is basically of two types ie. horizontal and vertical. Since by doing sharding, we are already horizontally partitioning tables across the shard nodes but we can still partition tables in one shard for better performance. For example, take below 2 cases:
- In the post table, we can partition the post table vertically. As post content is text type can be long size text, which can increase table size very rapidly, we can store post content in another table or in some key-value store system(NoSQL). This will help in performance improvement.
- As there can be thousands of comments and likes for a post, we can partition the comments and likes table horizontally in the same shard using the post id hash or putting some virtual column(expression-based horizontal partition or interval partition post created month).
Apart from Partioning, we can replicate both the lookup table and the user table across all shards. This will help in executing queries by using joins.
The flow of Some Functional Requirements
User Activities
For all use activities, the client will send requests to Backend API services via API Gateway. API Backend will call Data API to perform data read-write into OLTP.
For write requests, API backends will update the cache, and for read first API backend will try to get data from the cache. We can also leverage caching in Data API services to improve performance.
For each user activity API backend services will publish the activity message to the message broker to do OLAP processing. OLAP will also update data in the cache and OLTP.
User’s TimeLine
When any user opens the client app, the first thing he sees is his timeline. So rending a user’s timeline in milli seconds latency is very critical for a great user experience.
To Build a timeline we can think to show his friends and followers post updates, notification counts, and a list of notifications and other updates. To build a timeline we can use a ranking system with parameters like date create, no of like, no of comments, no of views, etc.
To provide a great user experience we need to show a timeline in very less time for this we can use background processing to keep updating the user’s timeline in a scheduled interval in the cache. Here we can also filter users by their activity frequency means we will keep updating the user’s timeline according to his/her activeness in the service.
After showing the user’s timeline from the cache, we can send another request to update the user’s timeline immediately with the latest updates.
Post Rendering
As in design, we are using CDN for the delivery of media files, we can also leverage CDN to search post-rending. We just need to configure the post rending service as a source for CDN and send CDN URL as a post URL. In case of post edit, we can make the post URL with a different version
Handling of Like, Comments, and Views
Post likes, comments, and views are asynchronously written to the database because in many cases there will be thousands of events per second and synchronous write will cause problems. All these events are sent into a very scalable messaging system where they are processed in batches to OLAP and OLTP systems to handle bursts.
This message broker’s ques can also be used to update posts and users ‘KPIs and send real times notifications.
Analytics for real-time trends and #tags
In the OLAP system, we can use ElasticSearch for a period to compute trending topics and #tags. A background process will do the processing of post text to count topics, #tags, view, and other KPIs to rank topics and #tags.
Challenges Involved In the Development of Social Networking System
Social networking systems are platforms that allow users to interact with each other online. Developing such systems involves many challenges, a few are given below.
- Maintaining the performance and scalability of the system, especially when dealing with large volumes of data and traffic.
- Ensuring the security and privacy of user data, especially in the face of cyberattacks and malicious actors.
- Providing features and functionalities that meet the diverse needs and preferences of users, such as personalization, customization, and accessibility.
- Balancing the trade-offs between innovation and regulation, such as complying with ethical and legal standards while offering novel and creative services.
Basically, all non-functional requirements are challenges in developing such systems. But according to me scalability, performance, and legal compliance are some of the most challenging tasks.
A good architecture and system design can solve all these problems so one can say good system Architecture and design is the most challenging task.
If you go by all the items discussed in this post then we can say the design of the OLTP part is the most challenging, Data API, Database sharding, and Replication is the most challenging part.
Sample Tech Stack over public cloud
Now we can explore what tech stacks we can use to develop this service.
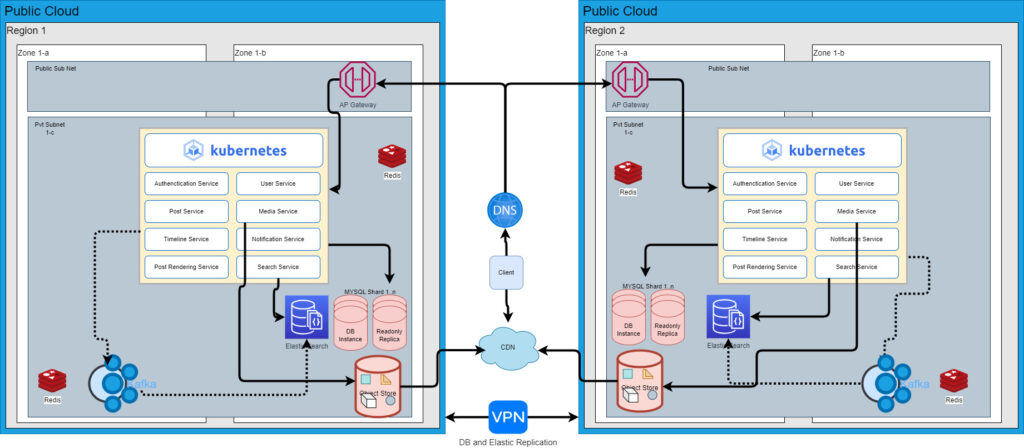
- K8S: For Microservices
- Redis culture for cache
- For OLTP, MYSQL sharded database with the regional replication or we can use both the Graph Database and RDBMS of our choice. Google cloud spanner is also a good choice for Managed Database which provides scaling, and replication across regions.
- For OLAP, Elastic Search with regional replication or Elastic Search with global Cassandra.
- Cloud object storage like S3
- Managed cloud CDN service
- Managed Cloud API gateway.
- Managed Kafa clustered with regional replication.
- Cloud-managed DNS service for regional request routing.